/** * This class is the equivalent of the Worker, but will simply use in an * external Executor thread pool. * * 这个类相当于工作人员,但是只会在一个外部执行器线程池中使用 */ protectedclassSocketProcessorimplementsRunnable {
if (status == SocketStatus.DISCONNECT && processor == null) { // 如果是断开连接状态且协议处理器为null //nothing more to be done endpoint requested a close //and there are no object associated with this connection return SocketState.CLOSED; }
SocketStatestate= SocketState.CLOSED; do { if (status == SocketStatus.DISCONNECT && !processor.isComet()) { // Do nothing here, just wait for it to get recycled // Don't do this for Comet we need to generate an end // event (see BZ 54022) } elseif (processor.isAsync() || state == SocketState.ASYNC_END) { state = processor.asyncDispatch(status); // 如果是异步的 } elseif (processor.isComet()) { state = processor.event(status); // 事件驱动??? } elseif (processor.isUpgrade()) { state = processor.upgradeDispatch(); // 升级转发??? } else { state = processor.process(socket); // 默认的 AbstractHttp11Processor.process } if (state != SocketState.CLOSED && processor.isAsync()) { state = processor.asyncPostProcess(); }
if (state == SocketState.UPGRADING) { // Get the UpgradeInbound handler UpgradeInboundinbound= processor.getUpgradeInbound(); // Release the Http11 processor to be re-used release(socket, processor, false, false); // Create the light-weight upgrade processor processor = createUpgradeProcessor(socket, inbound); inbound.onUpgradeComplete(); } } while (state == SocketState.ASYNC_END || state == SocketState.UPGRADING);
if (state == SocketState.LONG) { // In the middle of processing a request/response. Keep the // socket associated with the processor. Exact requirements // depend on type of long poll longPoll(socket, processor); } elseif (state == SocketState.OPEN) { // In keep-alive but between requests. OK to recycle // processor. Continue to poll for the next request. release(socket, processor, false, true); } elseif (state == SocketState.SENDFILE) { // Sendfile in progress. If it fails, the socket will be // closed. If it works, the socket will be re-added to the // poller release(socket, processor, false, false); } elseif (state == SocketState.UPGRADED) { // Need to keep the connection associated with the processor longPoll(socket, processor); } else { // Connection closed. OK to recycle the processor. if (!(processor instanceof UpgradeProcessor)) { release(socket, processor, true, false); } } return state; } catch(java.net.SocketException e) { // SocketExceptions are normal getLog().debug(sm.getString( "abstractConnectionHandler.socketexception.debug"), e); } catch (java.io.IOException e) { // IOExceptions are normal getLog().debug(sm.getString( "abstractConnectionHandler.ioexception.debug"), e); } // Future developers: if you discover any other // rare-but-nonfatal exceptions, catch them here, and log as // above. catch (Throwable e) { ExceptionUtils.handleThrowable(e); // any other exception or error is odd. Here we log it // with "ERROR" level, so it will show up even on // less-than-verbose logs. getLog().error( sm.getString("abstractConnectionHandler.error"), e); } // Don't try to add upgrade processors back into the pool if (!(processor instanceof UpgradeProcessor)) { release(socket, processor, true, false); } return SocketState.CLOSED; }
// Link objects request.setResponse(response); // 互相关联 response.setRequest(request);
// Set as notes req.setNote(ADAPTER_NOTES, request); res.setNote(ADAPTER_NOTES, response);
// Set query string encoding req.getParameters().setQueryStringEncoding // 解析 uri (connector.getURIEncoding());
}
if (connector.getXpoweredBy()) { // 网站安全狗IIS response.addHeader("X-Powered-By", POWERED_BY); }
booleancomet=false; booleanasync=false;
try {
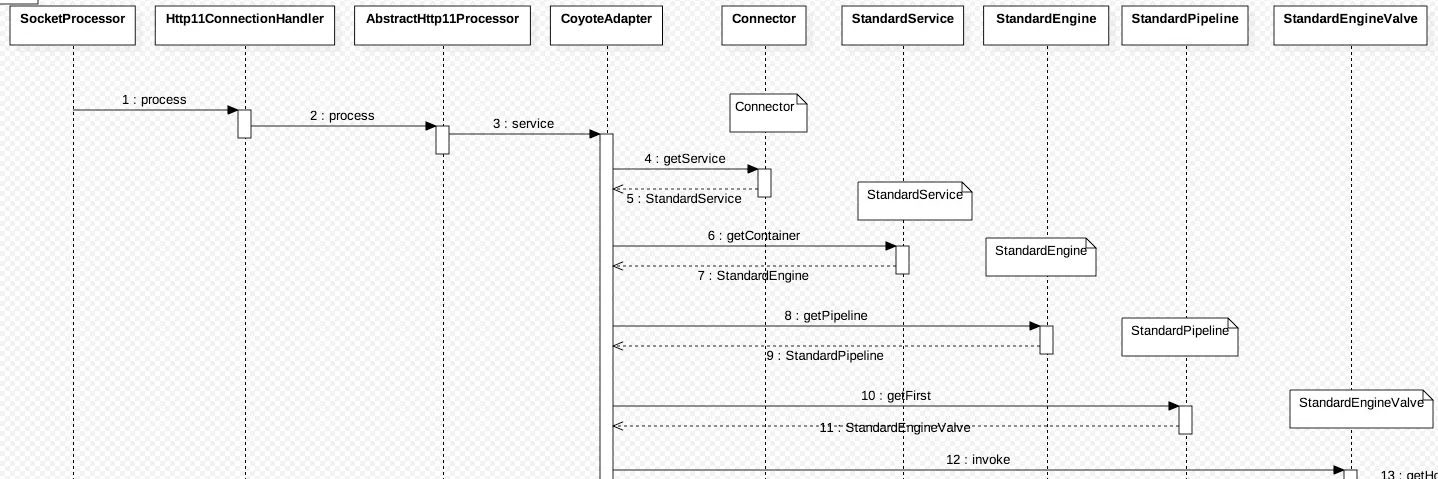
// Parse and set Catalina and configuration specific // request parameters req.getRequestProcessor().setWorkerThreadName(Thread.currentThread().getName()); booleanpostParseSuccess= postParseRequest(req, request, res, response); // 解析请求内容 if (postParseSuccess) { //check valves if we support async request.setAsyncSupported(connector.getService().getContainer().getPipeline().isAsyncSupported()); // Calling the container 调用 容器 connector.getService().getContainer().getPipeline().getFirst().invoke(request, response); // 一个复杂的调用
if (request.isComet()) { if (!response.isClosed() && !response.isError()) { if (request.getAvailable() || (request.getContentLength() > 0 && (!request.isParametersParsed()))) { // Invoke a read event right away if there are available bytes if (event(req, res, SocketStatus.OPEN)) { comet = true; res.action(ActionCode.COMET_BEGIN, null); } } else { comet = true; res.action(ActionCode.COMET_BEGIN, null); } } else { // Clear the filter chain, as otherwise it will not be reset elsewhere // since this is a Comet request request.setFilterChain(null); } }
} AsyncContextImplasyncConImpl= (AsyncContextImpl)request.getAsyncContext(); if (asyncConImpl != null) { async = true; } elseif (!comet) { request.finishRequest(); response.finishResponse(); if (postParseSuccess && request.getMappingData().context != null) { // Log only if processing was invoked. // If postParseRequest() failed, it has already logged it. // If context is null this was the start of a comet request // that failed and has already been logged. ((Context) request.getMappingData().context).logAccess( request, response, System.currentTimeMillis() - req.getStartTime(), false); } req.action(ActionCode.POST_REQUEST , null); }
} catch (IOException e) { // Ignore } finally { req.getRequestProcessor().setWorkerThreadName(null); // Recycle the wrapper request and response if (!comet && !async) { request.recycle(); response.recycle(); } else { // Clear converters so that the minimum amount of memory // is used by this processor request.clearEncoders(); response.clearEncoders(); } }
// XXX the processor may have set a correct scheme and port prior to this point, // in ajp13 protocols dont make sense to get the port from the connector... // otherwise, use connector configuration if (! req.scheme().isNull()) { // use processor specified scheme to determine secure state request.setSecure(req.scheme().equals("https")); } else { // use connector scheme and secure configuration, (defaults to // "http" and false respectively) req.scheme().setString(connector.getScheme()); request.setSecure(connector.getSecure()); }
// FIXME: the code below doesnt belongs to here, // this is only have sense // in Http11, not in ajp13.. // At this point the Host header has been processed. // Override if the proxyPort/proxyHost are set StringproxyName= connector.getProxyName(); intproxyPort= connector.getProxyPort(); if (proxyPort != 0) { req.setServerPort(proxyPort); } if (proxyName != null) { req.serverName().setString(proxyName); }
// Copy the raw URI to the decodedURI MessageBytesdecodedURI= req.decodedURI(); decodedURI.duplicate(req.requestURI());
// Parse the path parameters. This will: // - strip out the path parameters // - convert the decodedURI to bytes parsePathParameters(req, request);
// URI decoding // %xx decoding of the URL try { req.getURLDecoder().convert(decodedURI, false); } catch (IOException ioe) { res.setStatus(400); res.setMessage("Invalid URI: " + ioe.getMessage()); connector.getService().getContainer().logAccess( request, response, 0, true); returnfalse; } // Normalization if (!normalize(req.decodedURI())) { res.setStatus(400); res.setMessage("Invalid URI"); connector.getService().getContainer().logAccess( request, response, 0, true); returnfalse; } // Character decoding convertURI(decodedURI, request); // Check that the URI is still normalized if (!checkNormalize(req.decodedURI())) { res.setStatus(400); res.setMessage("Invalid URI character encoding"); connector.getService().getContainer().logAccess( request, response, 0, true); returnfalse; }
// Set the remote principal Stringprincipal= req.getRemoteUser().toString(); if (principal != null) { request.setUserPrincipal(newCoyotePrincipal(principal)); }
// Set the authorization type Stringauthtype= req.getAuthType().toString(); if (authtype != null) { request.setAuthType(authtype); }
// Request mapping. MessageBytes serverName; if (connector.getUseIPVHosts()) { serverName = req.localName(); if (serverName.isNull()) { // well, they did ask for it res.action(ActionCode.REQ_LOCAL_NAME_ATTRIBUTE, null); } } else { serverName = req.serverName(); } if (request.isAsyncStarted()) { //TODO SERVLET3 - async //reset mapping data, should prolly be done elsewhere request.getMappingData().recycle(); }
booleanmapRequired=true; Stringversion=null;
while (mapRequired) { if (version != null) { // Once we have a version - that is it mapRequired = false; } // This will map the the latest version by default connector.getMapper().map(serverName, decodedURI, version, request.getMappingData()); request.setContext((Context) request.getMappingData().context); request.setWrapper((Wrapper) request.getMappingData().wrapper);
// Single contextVersion therefore no possibility of remap if (request.getMappingData().contexts == null) { mapRequired = false; }
// If there is no context at this point, it is likely no ROOT context // has been deployed if (request.getContext() == null) { res.setStatus(404); res.setMessage("Not found"); // No context, so use host Hosthost= request.getHost(); // Make sure there is a host (might not be during shutdown) if (host != null) { host.logAccess(request, response, 0, true); } returnfalse; }
// Now we have the context, we can parse the session ID from the URL // (if any). Need to do this before we redirect in case we need to // include the session id in the redirect StringsessionID=null; if (request.getServletContext().getEffectiveSessionTrackingModes() .contains(SessionTrackingMode.URL)) {
// Get the session ID if there was one sessionID = request.getPathParameter( SessionConfig.getSessionUriParamName( request.getContext())); if (sessionID != null) { request.setRequestedSessionId(sessionID); request.setRequestedSessionURL(true); } }
// Look for session ID in cookies and SSL session parseSessionCookiesId(req, request); parseSessionSslId(request);
sessionID = request.getRequestedSessionId();
if (mapRequired) { if (sessionID == null) { // No session means no possibility of needing to remap mapRequired = false; } else { // Find the context associated with the session Object[] objs = request.getMappingData().contexts; for (inti= (objs.length); i > 0; i--) { Contextctxt= (Context) objs[i - 1]; if (ctxt.getManager().findSession(sessionID) != null) { // Was the correct context already mapped? if (ctxt.equals(request.getMappingData().context)) { mapRequired = false; } else { // Set version so second time through mapping the // correct context is found version = ctxt.getWebappVersion(); // Reset mapping request.getMappingData().recycle(); break; } } } if (version == null) { // No matching context found. No need to re-map mapRequired = false; } } } if (!mapRequired && request.getContext().getPaused()) { // Found a matching context but it is paused. Mapping data will // be wrong since some Wrappers may not be registered at this // point. try { Thread.sleep(1000); } catch (InterruptedException e) { // Should never happen } // Reset mapping request.getMappingData().recycle(); mapRequired = true; } }
// Possible redirect MessageBytesredirectPathMB= request.getMappingData().redirectPath; if (!redirectPathMB.isNull()) { StringredirectPath= urlEncoder.encode(redirectPathMB.toString()); Stringquery= request.getQueryString(); if (request.isRequestedSessionIdFromURL()) { // This is not optimal, but as this is not very common, it // shouldn't matter redirectPath = redirectPath + ";" + SessionConfig.getSessionUriParamName( request.getContext()) + "=" + request.getRequestedSessionId(); } if (query != null) { // This is not optimal, but as this is not very common, it // shouldn't matter redirectPath = redirectPath + "?" + query; } response.sendRedirect(redirectPath); request.getContext().logAccess(request, response, 0, true); returnfalse; }
// Filter trace method if (!connector.getAllowTrace() && req.method().equalsIgnoreCase("TRACE")) { Wrapperwrapper= request.getWrapper(); Stringheader=null; if (wrapper != null) { String[] methods = wrapper.getServletMethods(); if (methods != null) { for (int i=0; i<methods.length; i++) { if ("TRACE".equals(methods[i])) { continue; } if (header == null) { header = methods[i]; } else { header += ", " + methods[i]; } } } } res.setStatus(405); res.addHeader("Allow", header); res.setMessage("TRACE method is not allowed"); request.getContext().logAccess(request, response, 0, true); returnfalse; }
/** * Select the appropriate child Host to process this request, * based on the requested server name. If no matching Host can * be found, return an appropriate HTTP error. * * 根据所请求的服务器名称选择适当的子主机来处理这个请求。如果找不到匹配的主机,则返回一个适当的HTTP错误。 * */ @Override publicfinalvoidinvoke(Request request, Response response) throws IOException, ServletException {
// Select the Host to be used for this Request Hosthost= request.getHost(); if (host == null) { response.sendError (HttpServletResponse.SC_BAD_REQUEST, sm.getString("standardEngine.noHost", request.getServerName())); return; } if (request.isAsyncSupported()) { request.setAsyncSupported(host.getPipeline().isAsyncSupported()); }
// Ask this Host to process this request host.getPipeline().getFirst().invoke(request, response);
// Select the Context to be used for this Request Contextcontext= request.getContext(); if (context == null) { response.sendError (HttpServletResponse.SC_INTERNAL_SERVER_ERROR, sm.getString("standardHost.noContext")); return; }
// Bind the context CL to the current thread if( context.getLoader() != null ) { // Not started - it should check for availability first // This should eventually move to Engine, it's generic. if (Globals.IS_SECURITY_ENABLED) { PrivilegedAction<Void> pa = newPrivilegedSetTccl( context.getLoader().getClassLoader()); AccessController.doPrivileged(pa); } else { Thread.currentThread().setContextClassLoader (context.getLoader().getClassLoader()); } } if (request.isAsyncSupported()) { request.setAsyncSupported(context.getPipeline().isAsyncSupported()); }
// Don't fire listeners during async processing // If a request init listener throws an exception, the request is // aborted booleanasyncAtStart= request.isAsync(); // An async error page may dispatch to another resource. This flag helps // ensure an infinite error handling loop is not entered booleanerrorAtStart= response.isError(); if (asyncAtStart || context.fireRequestInitEvent(request)) {
// Ask this Context to process this request try { context.getPipeline().getFirst().invoke(request, response); } catch (Throwable t) { ExceptionUtils.handleThrowable(t); if (errorAtStart) { container.getLogger().error("Exception Processing " + request.getRequestURI(), t); } else { request.setAttribute(RequestDispatcher.ERROR_EXCEPTION, t); throwable(request, response, t); } } // If the request was async at the start and an error occurred then // the async error handling will kick-in and that will fire the // request destroyed event *after* the error handling has taken // place if (!(request.isAsync() || (asyncAtStart && request.getAttribute( RequestDispatcher.ERROR_EXCEPTION) != null))) { // Protect against NPEs if context was destroyed during a // long running request. if (context.getState().isAvailable()) { if (!errorAtStart) { // Error page processing response.setSuspended(false); Throwablet= (Throwable) request.getAttribute( RequestDispatcher.ERROR_EXCEPTION); if (t != null) { throwable(request, response, t); } else { status(request, response); } } context.fireRequestDestroyEvent(request); } } }
// Access a session (if present) to update last accessed time, based on a // strict interpretation of the specification if (ACCESS_SESSION) { request.getSession(false); }
// Restore the context classloader if (Globals.IS_SECURITY_ENABLED) { PrivilegedAction<Void> pa = newPrivilegedSetTccl( StandardHostValve.class.getClassLoader()); AccessController.doPrivileged(pa); } else { Thread.currentThread().setContextClassLoader (StandardHostValve.class.getClassLoader()); } }
// Disallow any direct access to resources under WEB-INF or META-INF MessageBytesrequestPathMB= request.getRequestPathMB(); if ((requestPathMB.startsWithIgnoreCase("/META-INF/", 0)) || (requestPathMB.equalsIgnoreCase("/META-INF")) || (requestPathMB.startsWithIgnoreCase("/WEB-INF/", 0)) || (requestPathMB.equalsIgnoreCase("/WEB-INF"))) { response.sendError(HttpServletResponse.SC_NOT_FOUND); return; }
// Select the Wrapper to be used for this Request Wrapperwrapper= request.getWrapper(); if (wrapper == null || wrapper.isUnavailable()) { response.sendError(HttpServletResponse.SC_NOT_FOUND); return; }
// Initialize local variables we may need booleanunavailable=false; Throwablethrowable=null; // This should be a Request attribute... long t1=System.currentTimeMillis(); requestCount++; StandardWrapperwrapper= (StandardWrapper) getContainer(); Servletservlet=null; Contextcontext= (Context) wrapper.getParent(); // Check for the application being marked unavailable if (!context.getState().isAvailable()) { response.sendError(HttpServletResponse.SC_SERVICE_UNAVAILABLE, sm.getString("standardContext.isUnavailable")); unavailable = true; }
// Check for the servlet being marked unavailable if (!unavailable && wrapper.isUnavailable()) { container.getLogger().info(sm.getString("standardWrapper.isUnavailable", wrapper.getName())); longavailable= wrapper.getAvailable(); if ((available > 0L) && (available < Long.MAX_VALUE)) { response.setDateHeader("Retry-After", available); response.sendError(HttpServletResponse.SC_SERVICE_UNAVAILABLE, sm.getString("standardWrapper.isUnavailable", wrapper.getName())); } elseif (available == Long.MAX_VALUE) { response.sendError(HttpServletResponse.SC_NOT_FOUND, sm.getString("standardWrapper.notFound", wrapper.getName())); } unavailable = true; }
// Identify if the request is Comet related now that the servlet has been allocated booleancomet=false; if (servlet instanceof CometProcessor && request.getAttribute( Globals.COMET_SUPPORTED_ATTR) == Boolean.TRUE) { comet = true; request.setComet(true); } MessageBytesrequestPathMB= request.getRequestPathMB(); DispatcherTypedispatcherType= DispatcherType.REQUEST; if (request.getDispatcherType()==DispatcherType.ASYNC) dispatcherType = DispatcherType.ASYNC; request.setAttribute(Globals.DISPATCHER_TYPE_ATTR,dispatcherType); request.setAttribute(Globals.DISPATCHER_REQUEST_PATH_ATTR, requestPathMB); // Create the filter chain for this request ApplicationFilterFactoryfactory= ApplicationFilterFactory.getInstance(); ApplicationFilterChainfilterChain= factory.createFilterChain(request, wrapper, servlet); // Reset comet flag value after creating the filter chain request.setComet(false);
// Call the filter chain for this request // NOTE: This also calls the servlet's service() method try { if ((servlet != null) && (filterChain != null)) { // Swallow output if needed if (context.getSwallowOutput()) { try { SystemLogHandler.startCapture(); if (request.isAsyncDispatching()) { //TODO SERVLET3 - async ((AsyncContextImpl)request.getAsyncContext()).doInternalDispatch(); } elseif (comet) { filterChain.doFilterEvent(request.getEvent()); request.setComet(true); } else { filterChain.doFilter(request.getRequest(), response.getResponse()); } } finally { Stringlog= SystemLogHandler.stopCapture(); if (log != null && log.length() > 0) { context.getLogger().info(log); } } } else { if (request.isAsyncDispatching()) { //TODO SERVLET3 - async ((AsyncContextImpl)request.getAsyncContext()).doInternalDispatch(); } elseif (comet) { request.setComet(true); filterChain.doFilterEvent(request.getEvent()); } else { filterChain.doFilter (request.getRequest(), response.getResponse()); } }
// Release the filter chain (if any) for this request if (filterChain != null) { if (request.isComet()) { // If this is a Comet request, then the same chain will be used for the // processing of all subsequent events. filterChain.reuse(); } else { filterChain.release(); } }
@Override public Servlet allocate()throws ServletException {
// If we are currently unloading this servlet, throw an exception if (unloading) thrownewServletException (sm.getString("standardWrapper.unloading", getName()));
booleannewInstance=false; // If not SingleThreadedModel, return the same instance every time if (!singleThreadModel) {
// Load and initialize our instance if necessary if (instance == null) { synchronized (this) { if (instance == null) { try { if (log.isDebugEnabled()) log.debug("Allocating non-STM instance");
instance = loadServlet(); if (!singleThreadModel) { // For non-STM, increment here to prevent a race // condition with unload. Bug 43683, test case // #3 newInstance = true; countAllocated.incrementAndGet(); } } catch (ServletException e) { throw e; } catch (Throwable e) { ExceptionUtils.handleThrowable(e); thrownewServletException (sm.getString("standardWrapper.allocate"), e); } } } }
if (!instanceInitialized) { initServlet(instance); }
if (singleThreadModel) { if (newInstance) { // Have to do this outside of the sync above to prevent a // possible deadlock synchronized (instancePool) { instancePool.push(instance); nInstances++; } } } else { if (log.isTraceEnabled()) log.trace(" Returning non-STM instance"); // For new instances, count will have been incremented at the // time of creation if (!newInstance) { countAllocated.incrementAndGet(); } return (instance); } }
synchronized (instancePool) {
while (countAllocated.get() >= nInstances) { // Allocate a new instance if possible, or else wait if (nInstances < maxInstances) { try { instancePool.push(loadServlet()); nInstances++; } catch (ServletException e) { throw e; } catch (Throwable e) { ExceptionUtils.handleThrowable(e); thrownewServletException (sm.getString("standardWrapper.allocate"), e); } } else { try { instancePool.wait(); } catch (InterruptedException e) { // Ignore } } } if (log.isTraceEnabled()) log.trace(" Returning allocated STM instance"); countAllocated.incrementAndGet(); return instancePool.pop();