迁移微服务框架-SpringCloud-事后总结
我们这次主要讲4件事:
1 | 1. 什么是微服务? 什么是 springcloud? |
1. 什么是微服务? 什么是 springcloud?
引用维基百科:
微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成。系统中的各个微服务可被独立部署,各个微服务之间是松耦合的。每个微服务仅关注于完成一件任务并很好地完成该任务。在所有情况下,每个任务代表着一个小的业务能力。
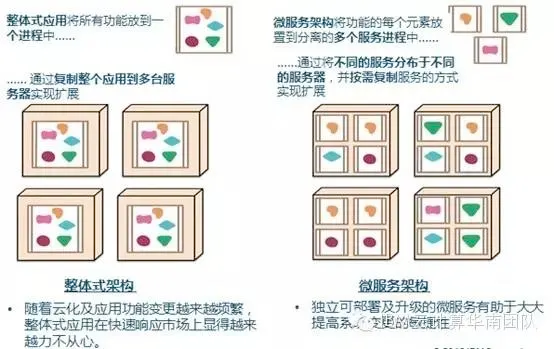
微服务架构的一些通用特性
- 通过服务实现应用的组件化:微服务架构中将组件定义为可被独立替换和升级的软件单元,在应用架构设计中通过将整体应用切分成可独立部署及升级的微服务方式进行组件化设计。
- 围绕业务能力组织服务(Organizedaround Business Capabilities):微服务架构采取以业务能力为出发点组织服务的策略,因此微服务团队的组织结构必须是跨功能的(如:既管应用,也管数据库)、强搭配的DevOps开发运维一体化团队,通常这些团队不会太大(如:亚马逊的“Two pizzateam”- 不超过12人).
- 产品而非项目模式:传统的应用模式是一个团队以项目模式开发完整的应用,开发完成后就交付给运维团队负责维护;微服务架构则倡导一个团队应该如开发产品般负责一个“微服务”完整的生命周期,倡导“谁开发,谁运营”的开发运维一体化方法.
- 智能端点与管道扁平化:微服务架构主张将组件间通讯的相关业务逻辑/智能放在组件端点侧而非放在通讯组件中,通讯机制或组件应该尽量简单及松耦合。RESTful HTTP协议和仅提供消息路由功能的轻量级异步机制是微服务架构中最常用的通讯机制。
- “去中心化”治理:微服务架构则鼓励使用合适的工具完成各自的任务,每个微服务可以考虑选用最佳工具完成(如不同的编程语言).
- “去中心化”数据管理:微服务架构倡导采用多样性持久化的方法,让每个微服务管理其自有数据库,并允许不同微服务采用不同的数据持久化技术.
- 基础设施自动化:云化及自动化部署等技术极大地降低了微服务构建、部署和运维的难度,通过应用持续集成和持续交付等方法有助于达到加速推出市场的目的.
- 故障处理设计:微服务架构所带来的一个后果是必须考虑每个服务的失败容错机制。因此,微服务非常重视建立架构及业务相关指标的实时监控和日志机制.
- 演进式的设计:微服务应用更注重快速更新,因此系统的计会随时间不断变化及演进。微服务的设计受业务功能的生命周期等因素影响。如某应用是整体式应用,但逐渐朝微应用架构方向演进,整体式应用仍是核心,但新功能将使用应用所提供的API构建。再如在某微服务应用中,可替代性模块化设计的基本原则,在实施后发现某两个微服务经常必须同时更新,则这很可能意味着应将其合并为一个微服务.
更多微服务内容请移步:IBM developerWorks 中文社区:解析微服务架构
什么是 springcloud?
Spring Cloud是伴随着微服务的概念诞生的.基于 SpringBoot.
和 SpringCloud 密切相关的Netflix是一家什么公司?
Netflix是世界上最大的在线影片租赁提供商,向它的670万名顾客提供超过85,000部DVD电影的租赁服务,而且能向顾客提供4000多部影片或者电视剧的在线观看服务。公司的成功源自于能够提供超大数量的DVD,而且能够让顾客快速方便的挑选影片,同时免费递送。Netflix已经连续五次被评为顾客最满意的网站.
为什么 Netflix 要做 SpringCould? Netflix 和 SpringCloud 的前世今生.
1、首先,Netflix是一家做视频的网站,可以这么说该网站上的美剧应该是最火的。
2、Netflix是一家没有CTO的公司,正是这样的组织架构能使产品与技术无缝的沟通,从而能快速迭代出更优秀的产品。在当时软件敏捷开发中,Netflix的更新速度不亚于当年的微信后台变更,虽然微信比Netflix迟发展,但是当年微信的灰度发布和敏捷开发应该算是业界最猛的。
3、Netflix由于做视频的原因,访问量非常的大,从而促使其技术快速的发展在背后支撑着,也正是如此,Netflix开始把整体的系统往微服务上迁移。
4、Netflix的微服务做的不是最早的,但是确是最大规模的在生产级别微服务的尝试。也正是这种大规模的生产级别尝试,在服务器运维上依托AWS云。当然AWS云同样受益于Netflix的大规模业务不断的壮大。
5、Netflix的微服务大规模的应用,在技术上毫无保留的把一整套微服务架构核心技术栈开源了出来,叫做Netflix OSS,也正是如此,在技术上依靠开源社区的力量不断的壮大。
6、Spring Cloud是构建微服务的核心,而Spring Cloud是基于Spring Boot来开发的。
7、Pivotal在Netflix开源的一整套核心技术产品线的同时,做了一系列的封装,就变成了Spring Cloud;虽然Spring Cloud到现在为止不只有Netflix提供的方案可以集成,还有很多方案,但Netflix是最成熟的。
SpringCloud 有哪些牛逼的功能?
SpringCloud 号称拥有五虎将(即最常用的五个功能). 哪五虎将?
- Eureka 云端服务注册与发现.
- Zuul 动态路由, 服务网关.
- Hystrix 断路器.容灾管理工具.
- Spring Cloud Config 云端配置中心.
- Load Balance 负载均衡.
还有一些其他的功能, 比如事件总线, 配置管理 API, 轮询框架, Consul 可与 Docker 无缝集成, Sleuth 日志收集工具包, Data Flow 大数据操作工具, Security 安全工具包, Zookeeper 操作 ZK 的工具包, Stream 数据流操作开发包, 封装了 Redis, Rabbit, Kafka. Ribbon 负载均衡, Feign 声明式的 HTTP 客户端, Task 提供计划任务管理,任务调度框架, Cluster 提供 Leadership 选举, 类似 Zookeeper 选举. Starters 为 SpringCloud 提供开箱即用的依赖管理.
2. 我们为什么使用 SpringCloud?
让我们先来看看传统IT架构面临的一些问题:
- 使用传统的整体式架构应用开发系统,如CRM、ERP等大型应用,随着新需求的不断增加,企业更新和修复大型整体式应用变得越来越困难;
- 随着移动互联网的发展,企业被迫将其应用迁移至现代化UI界面架构以便能兼容移动设备,这要求企业能实现应用功能的快速上线;
我们为什么要使用 SpringCloud ?
现有的框架为多个 SpringBoot 的框架, 最明显的一个问题就是, 重复代码太多, 直接导致的问题就是修改一处, 其余地方都要修改, 代码难以维护. 比如一个User 这张表,可能每个 SpringBoot 都需要 User 表的查询功能, 但是除了 User 模块, 其余模块也要创建 User 相关的类和配置文件,一旦 User 表字段更改, 所有相关模块都要更改, 令人恐惧.
用 SpringCloud 能解决这个问题吗?
能. 只需要 User 开放一个 关于 User 表的查询接口, 其他模块调用此接口,就能实现之前的功能. 避免了大量的重复代码. 提高了代码的可维护性.第二个问题就是应用扩展问题, 只要企业快速发展, 所有的后端都不可避免的要实施分布式, 将一个大的服务拆分为一个个小服务, 保证系统的快速迭代和快速扩展. A 应用故障不会导致 B 应用也故障. 现有的框架无法支持横向扩展和快速迭代, 之前的架构成为我们的痛点。
用 SpringCloud 能解决这个问题吗?
SpringCloud 为分布式和微服务而生, 拆分巨型应用, 使得每个模块都独立, 根据业务拆分服务, 也可根据业务的改变合并服务, SpringCloud 支持集群部署异常简单, 且自带软负载均衡, 配合 Zuul 网关实现服务认证, 安全过滤等功能. SpringCloud 自带的断路器能够很好的容灾, 当某个服务不通时, 不会影响整个服务导致雪崩性的效应. 并且如果某个服务需要迭代, 其余模块可丝毫不受影响. 更改架构后能承受更高的并发和用户量。第三个问题是原有的代码无法支持分库分表,原有的表全部都再一个库种,业务高度耦合,难以维护,为了践行微服务“去中心化”数据管理的理念,每个服务管理其自有数据库,我们必须将表根据业务进行分割,以应对后期分库。
原有架构不清晰,水平扩展和快速迭代没有成熟和现行的技术方案,使用成熟的 SpringCloud 方案可以减少项目风险,提高应对风险的能力和应对业务快速变化的要求。
3. 如何使用 SpringCloud? 如何 Quick Start?
快速开始已经有很多文章.
[史上最简单的 SpringCloud 教程 | 终章]—–SpringCloud 终极入门
4. 老代码使用 springcloud 需要注意哪些坑?
目前我们重构老代码的主要方向是:
- 抽取重复代码变成对外的 Restful 接口供其他模块调用.
- 根据数据库进一步合理拆分业务, 为以后的拆分数据库做铺垫.
- 隔离业务和 Restful 接口模块和实体类模块, 以便所有模块依赖公有代码.
- 避免递归调用和多层调用, 尽量提供方就是提供方, 消费方就是消费方. 减少深层次调用, 方便排错.
- 模块与模块之间的通信和协作通过消息队列. 减少耦合.
- 对所有模块依赖的公有代码进行 Scan, 以方便后面的重构.
遇到了哪些问题呢?
- 我们使用了 SpringCloud 的 Feign Http 客户端, 作为消费方. Feign 请求提供方接口时根据需要传参数, 可以使用
@RequestParam()注解, 也可以使用@PathVariable路径传参. 也可以使用@RequestBody注解传对象,关于这三个注解的用法,需要注意一下他们的用法和坑点.
@RequestParam用法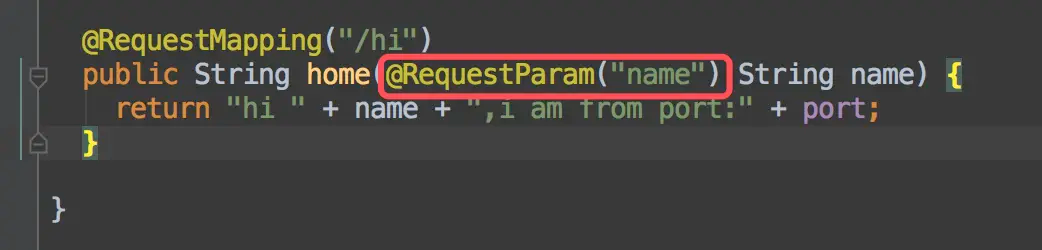
@RequestParam配合 GET 请求注解用于标注普通类型的参数, 比如8个基本类型和他们的包装类或者 String 类型. 也可用使用在 Map 上, 例如fun(@RequestParam ("map")Map<K,V> map), 也可以使用在 Date 类型上, 例如 fun(@RequestParam("date") Date date),注意, 只要有参数, 且参数是基本类型或者是包装类型和 String 类型, 必须使用该注解配合 GET 请求. 否则肯定报错.
@PathVariable()用法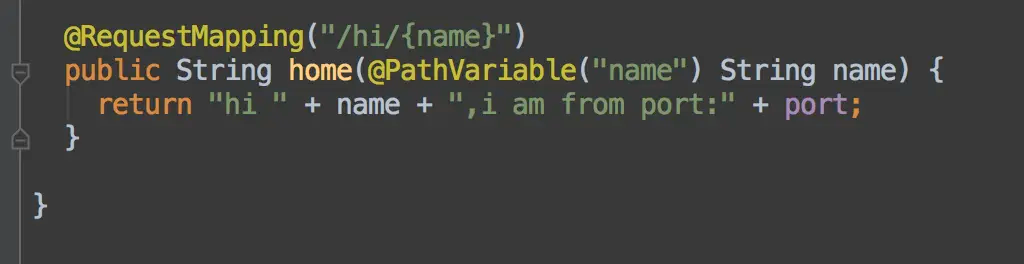
该注解用于配合路径中的占位符使用, 注意: 该注解必须在子类上也写上注解, 也就是说, 服务提供方的 API 接口 如果使用了该注解, 那么实现该接口的子类必须在参数前加上此注解, 这三个注解都不支持继承,因为Spring 是不能识别该注解应该作用于哪个参数, 如果不写, 就会得到 Null 值, 导致错误. 那么 @RequestParam 需要写吗? 答案是不需要写的, 因为@RequestParam是 url 传参, Spring 支持将参数名称映射到参数上给定的参数上. 因此, 使用该注解时需要注意的是: 必须在子类中加入该注解. 还有, 该注解不能传类似版本号的数字(如:1.2.1), 会导致 http 解析时去掉最后的小数点. 建议使用 URL中的www.google.com?name=tom 传参.
@RequestBody用法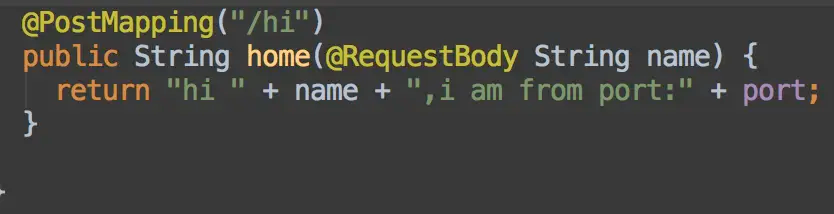
如果参数很多, 难道我们要一个一个参数写上去吗? 不需要, 我们可以使用@RequestBody 注解配合 POST 请求, 将多个参数封装成一个对象, 当然 @RerquestParam 注解配合 GET 加上 Map 参数也可以, 但是不建议使用 Map 作为参数, Map 会出现很多问题, 我们稍后再讲. 回到我们的@RequestBody 注解的用法上面来, 注意: 这个注解也必须在子类上声明, 否则参数无法映射. 因为 Spring 映射时找的是子类, 而该注解的作用是: 解析Body 里的内容变成 JSON, 然后映射到参数中, 如果不写, Spring 将不知道如何映射. 因为 Spirng 也是支持用流获取参数的. 并且该注解也是 Swagger 文档框架的基础. 注意, 一个方法中只能有一个@RequestBody注解. 注意: 该注解要求 Http 消息头中包含: Content-Type:Application/json.
总结一下上面关于三个注解的内容.
1 | 1. 实现类除(如果参数是map则需要加) 不需要加注解,其余都要加注解; |
- 还有一个坑点, 就是上面说的 Map 参数, 因为我们主要重构的是关于 Mapper 方法, 也就是数据库操作, 而这之前为了方便传参数, 使用了大量的 Map 作为参数的方法, 并且 Value 的泛型为 Object 类型, 这个时候问题就出现了, 如果之前 Map 中有个键值对是
data=new Date(), 在 xml 配置文件中则是create_date <= #{date}, 原本这样写是没有任何问题的. 但是一旦把 Map 作为网络调用的参数, 当你把 Date 类型传过去的时候, 而 Value 的泛型又是 Objece, 那么那边接受到的就是 Long 类型的时间戳, 在 xml 文件中就会出现create_date <= 1213244343432, 很明显, 就会溢出报错. 所以, 我们后期都将做了特殊处理, 类似下面这样:1
2
3
4
5public void function(Map<String, Object> map){
Long date = (Long)map.get("date");
// 将Long 类型转换成 Date 类型
map.put("date", new Date(date));
}
所以, 以后遇到需要传递 Date 类型的时候, 尽量不要使用 Map, 如果使用 Map, Value 的泛型也尽量不要写 Object.
3 . 还有一个问题就是分页插件的问题, 我们使用的 pageHelper 的开源分页插件, 原理是在当前线程中放入一个 ThreadLocal 的 Page 对象, 当调用动态代理了 mybatis 的方法时, 经过代理对象 invoke 方法时会触发继承了 Mybatis 拦截器的分页插件, 分页插件会从 ThreadLocal 中取出分页对象, 进行分页. 执行结束后会删除该 Page 对象.
那么我们发生一个什么故障呢? 原有的分页是这样写的:
1 | public List<User> getPageUser(User user){ |
这段代码之前写是没有任何问题的, 但是, 由于 UserMapper 被抽取出来成为公共部分代码. 所以这个地方被重构成:
1 | public List<User> getPageUser(User user){ |
可以看到, userMapper 变成了 userClient, 原有的 SQL 变成了网络调用. 那么这个时候会发生什么事情呢? PageHelper.start(page, rows); 放入线程的 Page 对象将不会被消费, 也不会被删除, 因为当前线程根本不会执行 Mybatis 的方法, 更不会进入拦截器, 而容器使用的是线程池, 当该方法结束后, 携带着 Page 对象的线程会随机分配一个任务执行 SQL, 如果该 SQL 不支持分页, 但是分页插件发现该线程中含有 Page 对象, 就会强行分页, 导致错误, 而这个错误很难排查. 所以, 当使用 PageHelper.start(page, rows);方法后, 在本任务执行结束之前一定要在本虚拟机中跟一条 SQL , 也就是跟一个 Mybatis 的方法. 否则将会影响其他线程中 SQL 的执行. 导致报错.
还有就是, 重构后, 实体类的全限定名都变化了, 如果使用缓存,或者是任何依赖序列化的中间件, 都会因为类名不对导致无法反序列化为新实体类而报错.
所以应该在保证安全的情况下, 将缓存清空.关于断路器的使用, 断路器的作用是, 如果
Feign调用失败, 并且重试多次失败(我的测试是5秒之内连续10次失败之后), 就会触发断路器, 也就是我们重写的方法, 刚开始, 我们直接在断路器中返回了默认值, 比如如果是对象就返回 null, 如果是容器就返回空, 如果是基本类型就返回默认值, 但是, 仔细一想不对, 如果业务代码将 null 和默认值作为逻辑判断怎么办, 实际上, 网络调用失败返回null和调用成功返回null是不同的. 因此, 我们将触发断路器方法中的内容改为了抛出异常. 避免影响老代码的逻辑, 可以在新代码的使用中, 针对断路器如何返回值做出新的约定. 防止断路器和业务返回内容混淆. 断路器什么时候会恢复调用呢?答案是5秒之后断路器会变成半开闭的状态,如果有服务请求,就会尝试调用一次,如果成功则关闭断路器,如果失败,则开启断路器。5秒之后就又变成了半开闭的状态。还有一个坑点就是: 如何传递
Header, , 我们需要的网络调用中传递Header, 而我们现有的Header都是存放在ThreadLocal中的, 难道我们要写一个Feign的配置类, 并在每个配置类上加上一个@Header的注解? 或者我们要将Header放在参数中传递吗? 答案是不必的. 我们只需要拦截Http Request, 在Http请求前加入我们需要的Header. 而这就引出了第七个问题。
- SpringCloud Feign 和断路器为了服务的高可用和应用健壮性, 提供了二种
隔离策略:线程池隔离和信号量隔离,简单说一下什么是
线程池隔离, SpringCloud将服务调用的主线程和 Feign 调用的Http请求分开存放在不同的线程池, 为什么要这么做呢?试想一下如果不分开存放, 当主线程调用时超时,那么 tomcat 就会阻塞大量线程,影响整个服务,但,如果使用线程池隔离, Feign 请求会开辟新的线程,就算超时也不影响整体应用的,更不影响tomcat 线程池中的线程,保证了容器的安全。
再说一下什么是
信号量隔离, 信号量就是系统设置的并发请求数,如果设置的信号量为10, 那么该服务接口的请求并发数就为10, 超过10就进行服务降级,忽略请求。信号量隔离是使用tomcat中的主线程进行服务请求,因此,不能算是隔离,只能算是限流,限制请求的数量,即使目标服务不通,也不会拖垮整个 tomcat 中的服务。如果请求的服务速度很快,并发很高,并且提供方服务稳定。那么使用信号量是合算的。因为不会有线程的上下文切换。否则使用线程池隔离比较合算。
那么对于我们来说,
隔离策略带给我们什么影响呢? 第6点的时候我们说,我们需要将Header传递, 而Header放在ThreadLocal 中,所以,线程池隔离的策略难以无缝支持ThreadLocal 中的Header。 除非特殊配置或者写在参数中,但这需要修改大量代码,我们想使用切面的方式将Header 透明的传递。信号量隔离策略和适合我们,既能保证服务的稳定性,也能保证服务中Header的传递。所以我们选择了信号量隔离。
由于分布式调用出错调试较为复杂, 因此, 以前返回客户端只是
服务端错误, 现在使用@ExceptionHandler(HystrixRuntimeException.class)注解, 细化每个异常, 用以返回不同的错误信息, 方便排错.测试用例在之前貌似不怎么重要, 因为一个 debug 可以一路调通, 但分布式的可能需要跨越多层调用, 因此, 单元测试就显得很重要, 能将错误慢慢分割. 从而更加快速精准的定位异常原因, 因此, 重构后增加了大量的测试用例, 用以排错.
统一配置类, 使用
@ComponentScans()注解扫描一个共同的配置模块, 方便重构和配置.否则, 大量的配置类将不同统一配置, 我们将疲于奔命.SpringCloud Feign 客户端第一次远程调用可能会失败, 原因是由于Spring 是懒加载的, 调用Feign需要加载很多类,需要一些时间, 而Feign 默认超时一秒就会认为服务调用失败, 抛出异常。 因此我们测试时只需要关注第二次调用即可。
总结:至此,我们知道了什么?
1 | 1. 什么是微服务? 什么是 springcloud? |