RocketMQ 异常分析 [TIMEOUT_CLEAN_QUEUE]broker Busy, Start Flow Control for a Whil
现象:
在对 RMQ 做集群压测时,偶现 [TIMEOUT_CLEAN_QUEUE]broker busy, start flow control for a whil 异常,对系统正确率有一定影响,所以决定一探究竟。
全局搜索代码
首先,clone 了一波代码,全局搜了一下,在 BrokerFastFailure 这个类里的 cleanExpiredRequestInQueue 方法看到了:
1 | void cleanExpiredRequestInQueue(final BlockingQueue<Runnable> blockingQueue, final long maxWaitTimeMillsInQueue) { |
这段代码逻辑:
- 如果当前时间减去这个请求的创建时间 > 配置的最大等待时间。就删除掉这个请求,并抛出这个异常。在调用 returnResponse 方法时,会直接调用 netty 的 writeAndFlush 方法写回数据。
而这个方法会被 4 个地方调用:
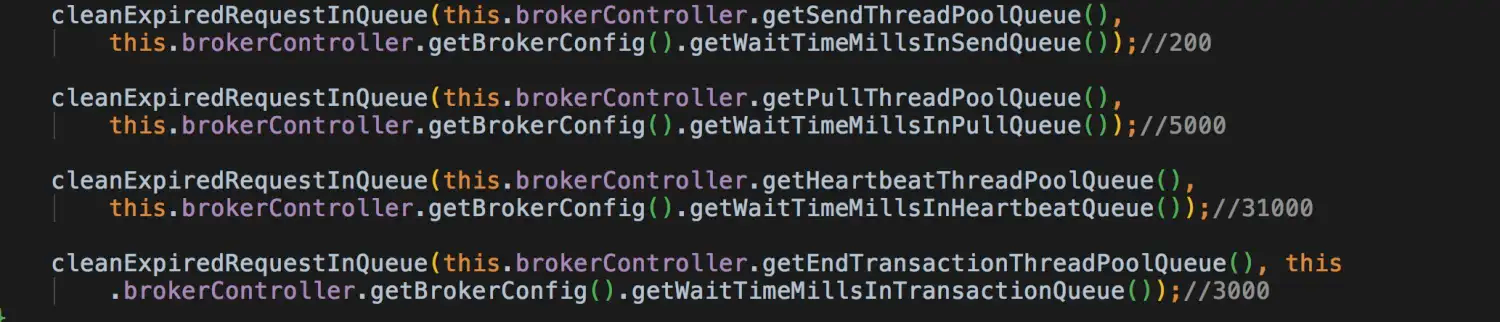
楼主在每个调用后面设置了默认值:
发送时:最大 200ms
pull 消息时: 最大 5 秒
心跳: 31 秒
事务: 3 秒。
而我们的系统都是在 send 消息时,报错的,看来,是队列里请求等待超过 200 毫秒了。
再回头看看 cleanExpiredRequest 这个方法。
这个方法被一个 10ms 间隔的定时任务执行的。因此,最多也就超过 210 毫秒,就会抛异常。而这个方法还有另外一个逻辑:
1 | while (this.brokerController.getMessageStore().isOSPageCacheBusy()) {// 如果写不进去. |
如果操作系统 PageCache 很忙,也抛出 PCBUSY 异常,忙的意思是:往 MQ 文件里写是需要一把锁的,如果上次上锁的时间截止到现在,超过了 1 秒,就表示忙,就不等了,就抛出异常。
明显,200ms 的队列排队超时,更容易被触发。
那有没有可能,把这个队列对应的线程池搞的大一点呢?
我们看看源码:
sendThreadPoolQueueCapacity = 10000;
sendMessageThreadPoolNums = 1;
发现这个队列的大小是 10000。线程池的大小是 1(max 和 core 都是 1).
为什么是1?
注释是这么说的:
thread numbers for send message thread pool, since spin lock will be used by default since 4.0.x, the default value is 1.
意思是,4.0.x 版本后使用自旋锁,所以默认值是1.
这个锁说的是 PutMessageLock,在 RMQ 里,有 2 种实现:
- PutMessageSpinLock 自旋锁。
- PutMessageReentrantLock JDK 非公平重入锁。
默认使用自旋锁,但是,自旋锁适合在并发低的时候使用,说白了就是乐观锁,乐观锁适合并发低的时候使用,悲观锁适合在并发高的时候使用。
为什么使用一个线程?因为多个线程没有效果,往 PageCache 里写数据是上锁的,最耗时的就在这部分,开启多个线程在这里抢锁是没有意义的。而且,在高并发下,多个线程自旋抢锁,CPU 可能会爆炸。
那用重入锁呢?大部分时候,MQ 的压力都没那么大,使用自旋锁,能够减少 CPU 上下文切换,提高性能。这是一个权衡。如果你把线程池搞了多个 线程,那就使用重入锁吧。但多线程确实没意义。
所以,线程池这部分,我们最好不要修改,也就是说,你即使增加线程数,也解决不了这个问题。另外,如果不是 1,在使用绝对顺序消息时,是无法保证消息的顺序的。相当于多个线程处理一个队列的消息,顺序一定会错乱。这个千万要注意。
根本的原因还是 PageCache 刷盘的时候,会有毛刺,超时超过 200ms,就会偶发这种现象。
总结
总结一下:
这个错误是因为请求在队列里待的太久了,如果是 send 请求,就是 200 多毫秒。因此,会被 Server 端认为这是过期的请求。
相关参数:
waitTimeMillsInSendQueue 这个最有效,默认值是 200,可稍微改的大一点。例如 250,300,切不可过大,过大会导致积压过多请求,而且大部分都是无效的。更会引起后面的请求都无效。
sendMessageThreadPoolNums 发送消息处理线程数,可以改的大一点,但治标不治本。
brokerFastFailureEnable 这个参数用于控制是否进行扫描,就是每 10ms 执行 cleanExpiredRequest 那个定时任务,可以修改为 false,但不建议这么做。
最后,这个错误的根本原因猜测是因为操作系统 IO 抖动,因为看到网上很多 tps 很低,也会出现这个情况。具体还需要详细的测试和排查。
通常,大家会使用重试策略,解决这个异常,但是可能会引起消息重复,所以,如果对消息重复敏感,做幂等是必须的。
如果 CPU 和 磁盘负载很高,出现这种问题就很正常了,建议增加 Broker 服务器,分担压力。