RocketMQ 线程模型分析
前言
RocketMQ 是个消息服务器,也是个网络服务器。
本文,将从网络 IO 模型,线程模型,看看 RocketMQ 是如何设计的。
IO 模型
IO 模型这块其实没什么好说的,这里稍微展开一下。
RocketMQ 使用了 Netty 作为网络通信框架,自然而然使用了 Ractor 模型,或者说 Select 模型、Epoll 模型。即一个线程管理 N 个 Socket 的模式,此模式可管理海量连接,基本是所有网络服务器的首选。
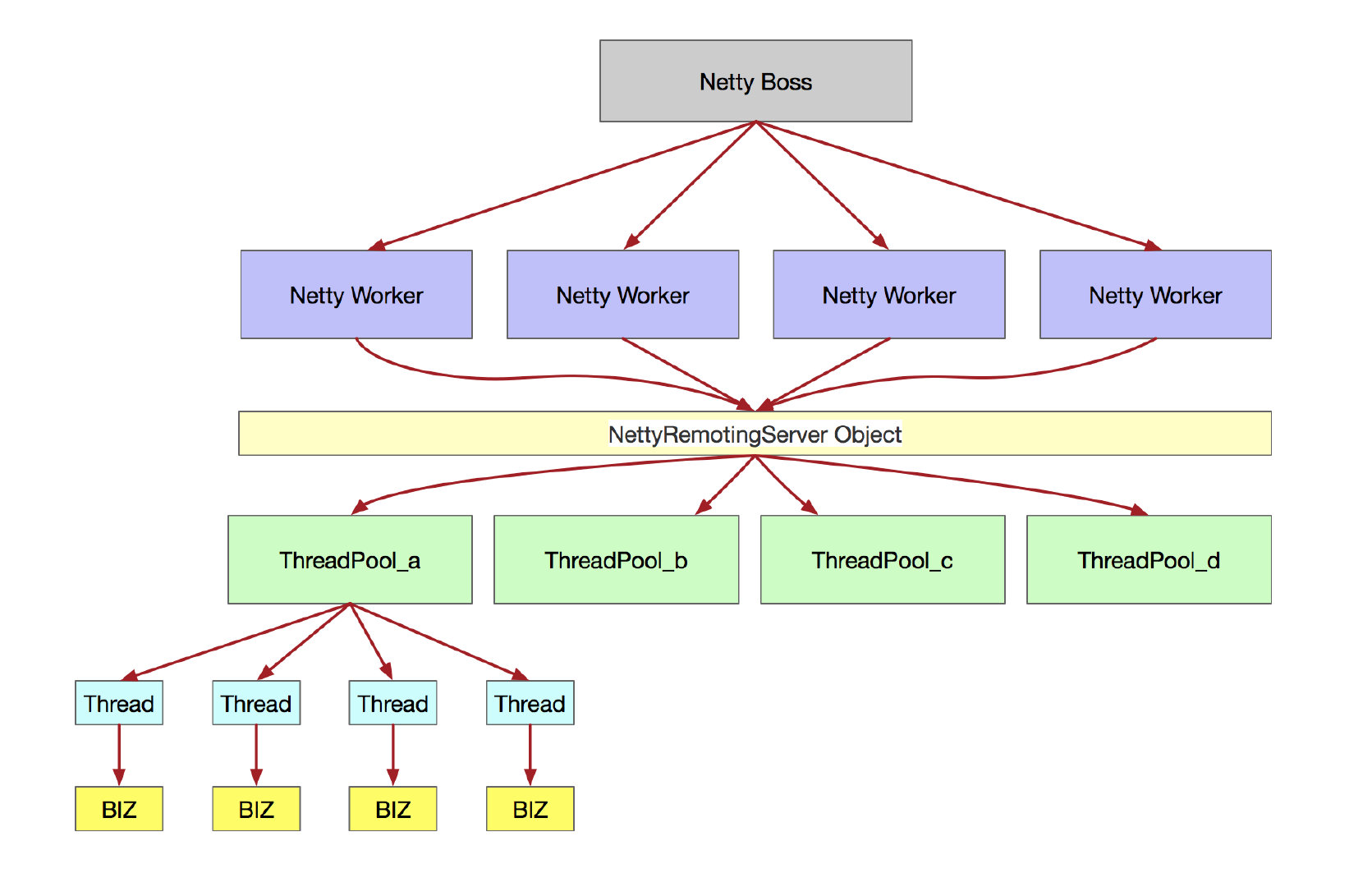
在这里,我们可以确定,RocketMQ 的 Boss 线程数为 1, Worker 线程数为 CPU * 2.
在说线程模型之前,先看看 RocketMQ 如何设计 Server 接口的。
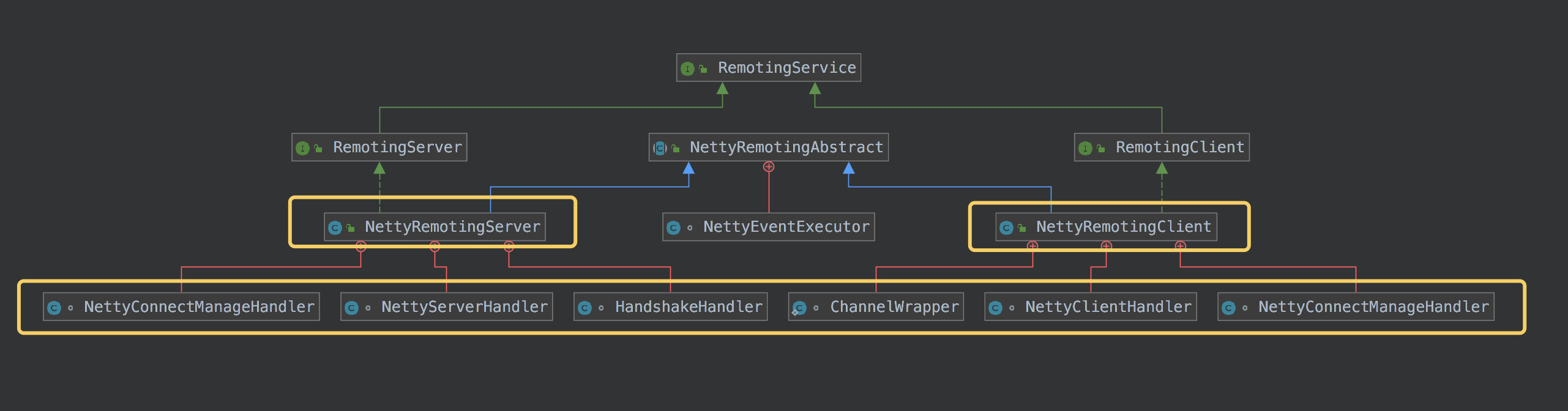
如上:
RemotingService 作为顶层接口,定义了 启动和关闭,另外还有注册 RPC 钩子,职责简单。他的两个子接口 RemotingServer 和 RemotingClient 各自增加了自己的抽象接口。
例如 Server 专属的 localListenPort 和 getProcessorPair ,Client 专属的 getNameServerAddressList 等。注意:两者都有 invokeSync 方法,但,参数不同,这也是因为他们自身的角色不同所影响的。
至于 NettyRemotingAbstract 抽象类,本人认为这只是个简单的”抽取重复代码”的“简单操作”。
再下面,就是具体实现类。每个类,都有内部类,都是 Netty 各种 Handler 的实现:
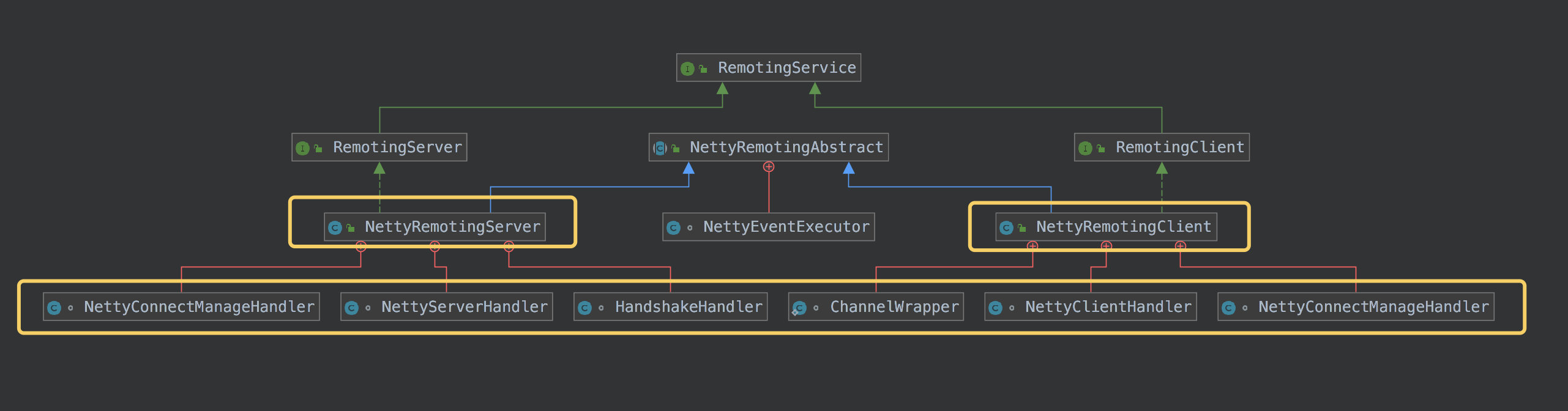
我们关注黄色框里的东西,
NettyConnectManageHandler 负责处理 注册,连接,异常等事件,继承自 ChannelDuplexHandler。
NettyServerHandler 则是关键的业务处理类,处理真正的 Msg,继承自 SimpleChannelInboundHandler
HandshakeHandler 负责处理握手程序,这里就不解释了。
以上 3 个是 Server 端的 Handler。都是 NettyRemotingServer 的内部类。Client 端暂时不表。
线程模型
NettyServerHandler 作为处理业务的关键类,每个 worker 线程都有自己的单独实例,但该类只是做个包装或者桥接而已,作用不大, NettyRemotingServer 才是关键。
当 Request 进入到 Server 中,MQ 会根据 请求类型 code 找到对应的处理器,MQ 有多种处理器,如下:
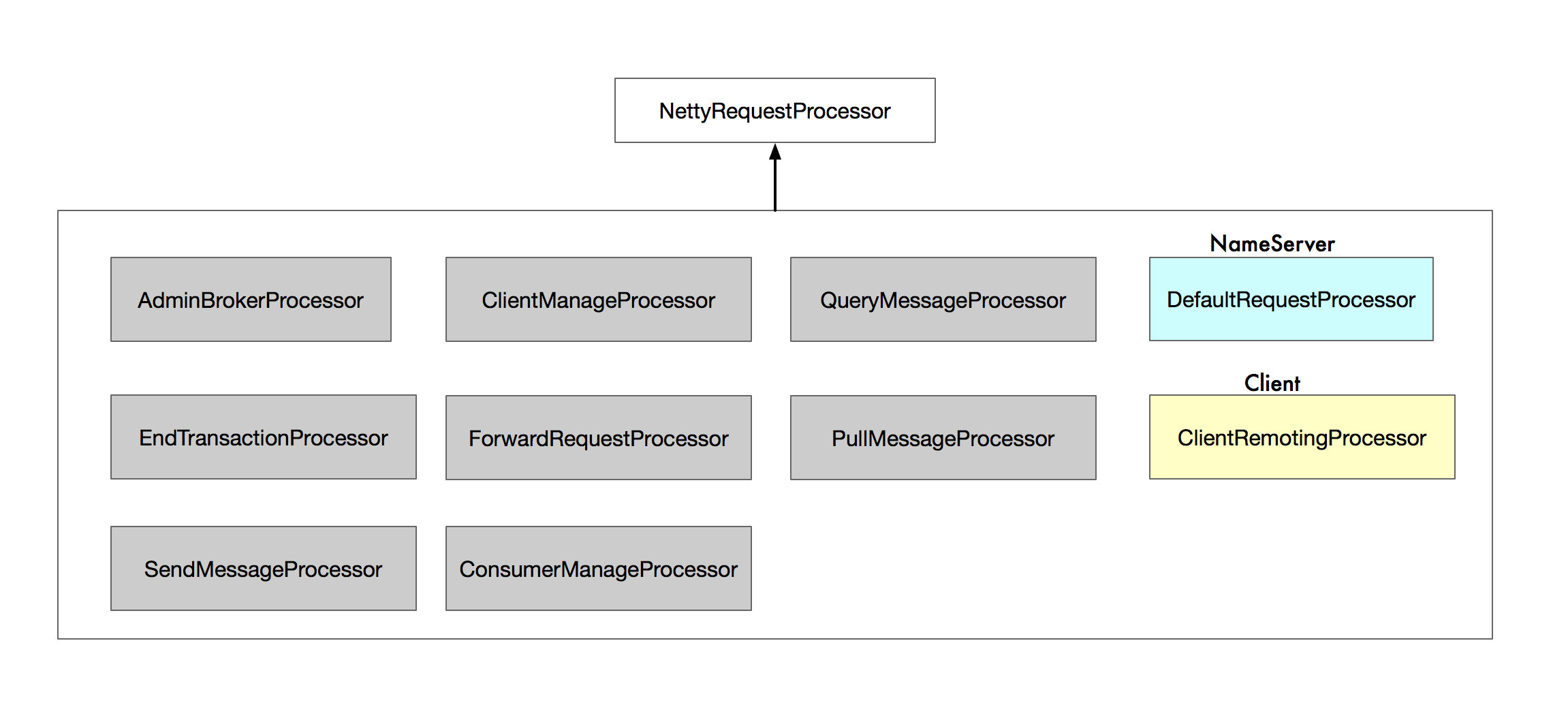
他们都继承自 NettyRequestProcessor 接口:

此接口只有 2 个方法,处理请求和拒绝请求,处理请求的参数是 Nettty 的 context 和自身的RemotingCommand 对象,这是个大对象:
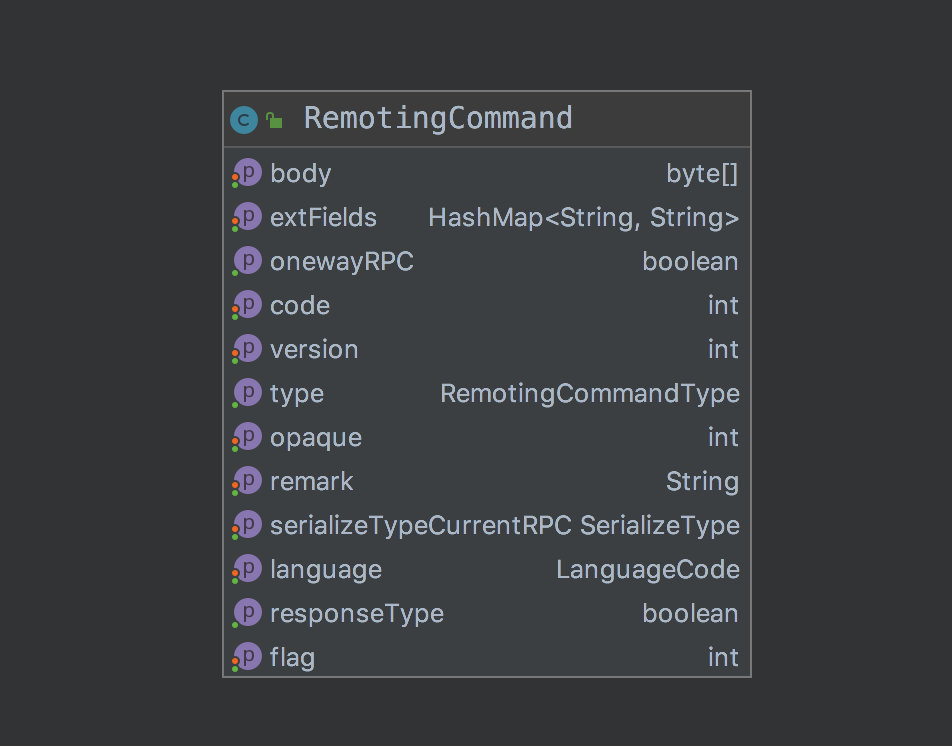
以上,是 RemotingCommand 的成员变量,这里说下 flag 的作用,其他就不说了。
flag 表示这次请求是什么类型。
倒数第一位,0 表示请求,1 表示返回。
倒数第二位,1 表示 oneWay。
扯远了。
刚刚提到 NettyRequestProcessor ,这是个处理器,在 MQ 中,每个 NettyRequestProcessor 都绑定了一个线程池,在 MQ 的抽象里,有个 Pair 对象,如下:
1 | public class Pair<T1, T2> { |
同时,还有个 Hash 表,用 code 映射了 Pair。如此,就实现了:通过请求 code 找到“线程池和处理这种请求的处理器”,然后,提交一个任务到该线程池,任务中,会调用该处理器的 processRequest 方法,或 rejectRequest 方法。
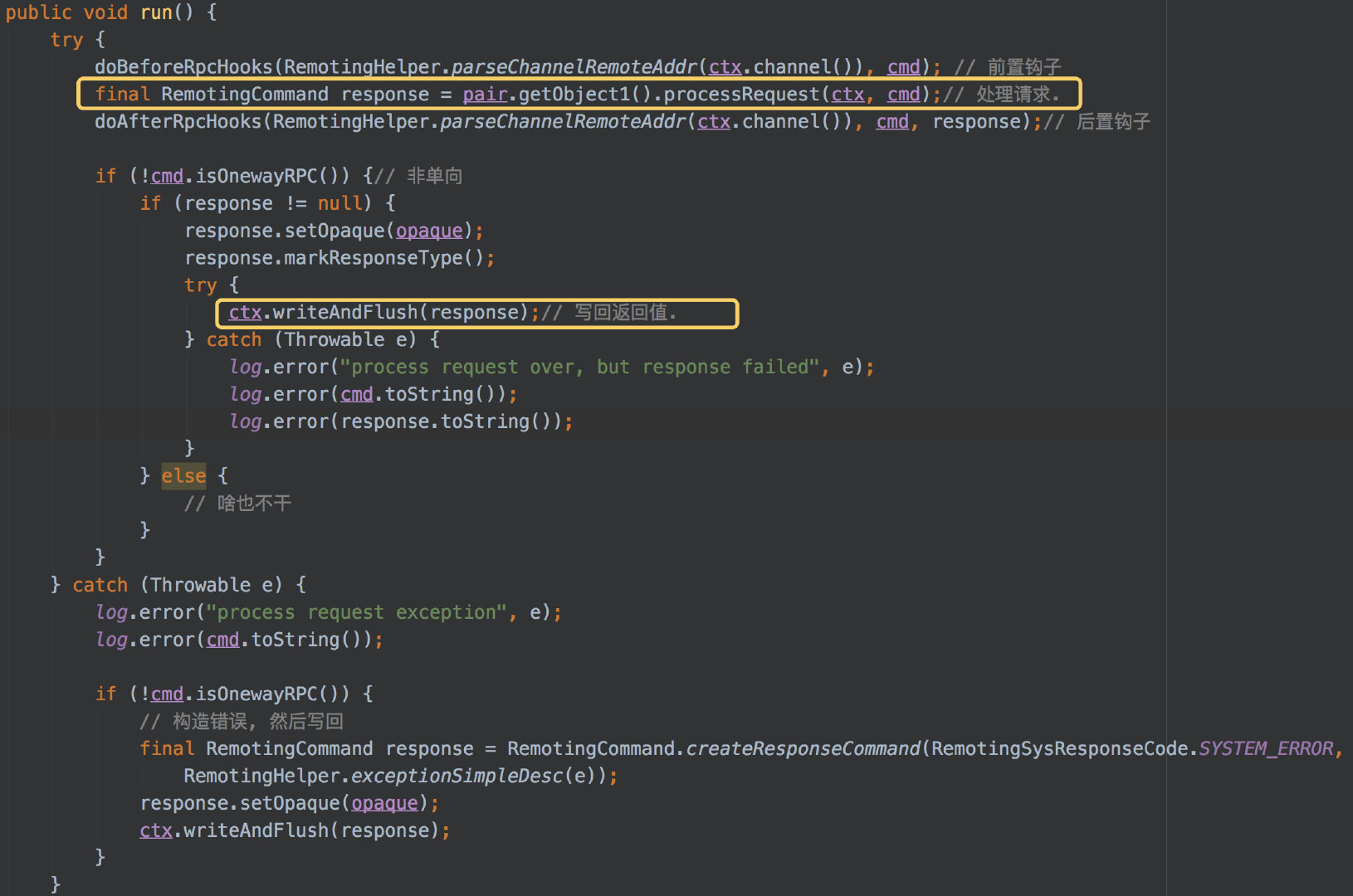
上图中,为处理请求的关键步骤。执行钩子就不说了,我们知道,设计代码时,关键步骤都加钩子,便于扩展和以后加代码。
其中,会调用 processRequest 方法,执行具体业务,并得到返回值。然后使用 netty 的 ctx 对象,将返回值直接写回 Socket。
如果发生错误了,也将错误构造成消息,写回客户端。
注意,这里一直有个操作 就是 response.setOpaque(opaque) ,就是设置请求 ID,这是 IO 多路复用的关键。
这里我们梳理一下,Netty 每次请求,都会调用 NettyRemotingServer 的 processRequestCommand 方法。
而 NettyRemotingServer 保存了请求 code 和 Pair<处理器,线程池> 的hash 映射表。
每次请求,根据 code 找到线程池,生成一个新任务,提交到线程池,任务里,会执行“处理器” 的processRequest 方法得到返回值,最后写回客户端。
MQ 为每种类型的任务,使用了不同的线程池,即线程池隔离。同时,也根据每种不同的任务类型,设置了不同的线程池参数。
例如:
Send 发送消息任务,线程池大小是1。
pull 拉取消息任务,线程池大小是 16 + CPU*2
query 查询任务,线程池大小是 8 + CPU*2;
当然还有其他的,这里就不枚举了,注意:大部分线程池都是多线程,只有 send 任务默认是单线程。
你猜是为什么呢?
send 操作是个写操作,最后是要上锁的,虽然锁的粒度已经足够小,但仍然是有锁的。如果是有锁的,多线程的是不划算的。这也是 RocketMQ 的设计决定的———— 只写一个 CommitLog。
假设,能像 Kafka 一样,同时写多个文件,是不是就可以利用多线程了呢?
当然,这里不是说多线程一定好,只是表达另外一种思路。如果单线程就能触发 MQ 瓶颈,多线程也没啥意义。
总结
千万句,汇成一幅图:
EOF