RocketMQ 和 Kafka 索引设计比较
概述
索引,是存储设计的关键,一个好的索引,应该能够在最短的时间里,找到你想要的数据,同时,还能尽量少的使用内存或磁盘空间。
今天不谈 MySQL 或者 NoSQL 这些数据库索引,谈谈相对而言较为简单的 MQ 索引。通过研究 MQ 的索引,看看他们为何如此设计,我们又有哪些借鉴之处。
RocketMQ
RocketMQ 的数据文件属于混合存储,即,所有的 topic 数据都放在一个文件里,因此,读数据的时候,就无法做到连续读了,只能随机读,所以 RocketMQ 推荐使用大内存,利用 PageCache 预读机制把 commitlog 数据缓存起来,而混合存储的好处则是能够承受万级别的队列数量。
下图为阿里云某篇文章对 RocketMQ 和 kafka 进行的“不同数量 topic 对性能的影响”测试,每个 topic 都是 8 个 queue 或者 8 个 partition。文章测试结果如下:
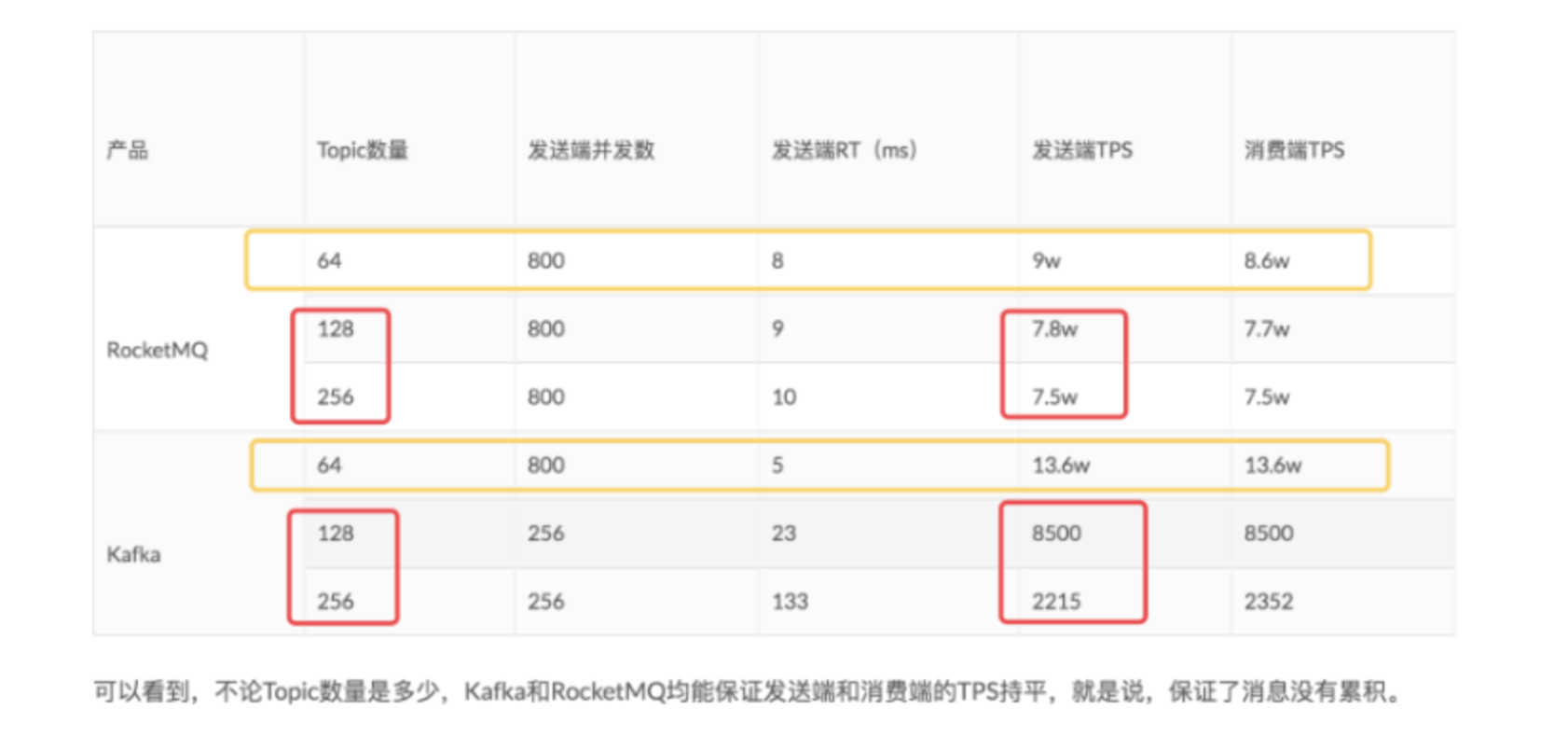
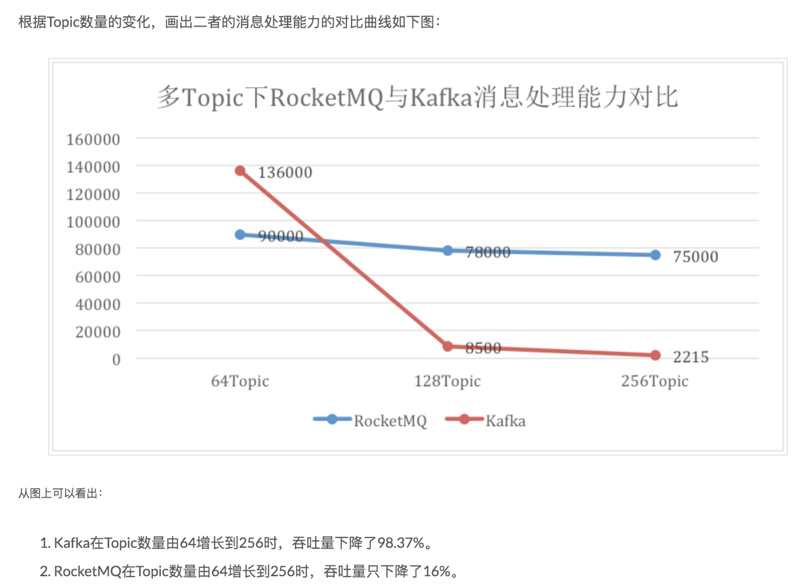
文章地址:http://jm.taobao.org/2016/04/07/kafka-vs-rocketmq-topic-amout/
怎么说呢?很强。
当然,华为云的老哥也做了一些回应:https://bbs.huaweicloud.com/blogs/113911
华为老哥表示 kafka 64 分区有些夸张,单机单磁盘 1000 分区还是没啥问题的(最好别超过 2000)。
这不是说索引的,跑偏了。回来。
RocketMQ 提供基于 MsgID 搜索消息的方案,即,每条消息,都有一个唯一的 ID,ID 由 broker IP + Port + CommitLog Offset 组成,通过这两个参数,可快速定位到一条消息。注意,Kafka 是没有这个功能的,但理论上,通过 Kafka 的 offset 也是可以找到具体的消息的,下面会详细说。
另外 RocketMQ 有 2 种索引。
- 消息消费索引
- Hash 查询索引
消息消费索引
消息消费索引,可以理解为,就是 topic 的索引数据,类似 kafka 的索引数据。如果没有这个,消费者基本就找不到消息了。这个索引里,存放着对应 topic 、对应 queue 里的消息连续 offset 集合(不像 commitLog 是混合存储的)。
下图为 RocketMQ 的存储设计图:
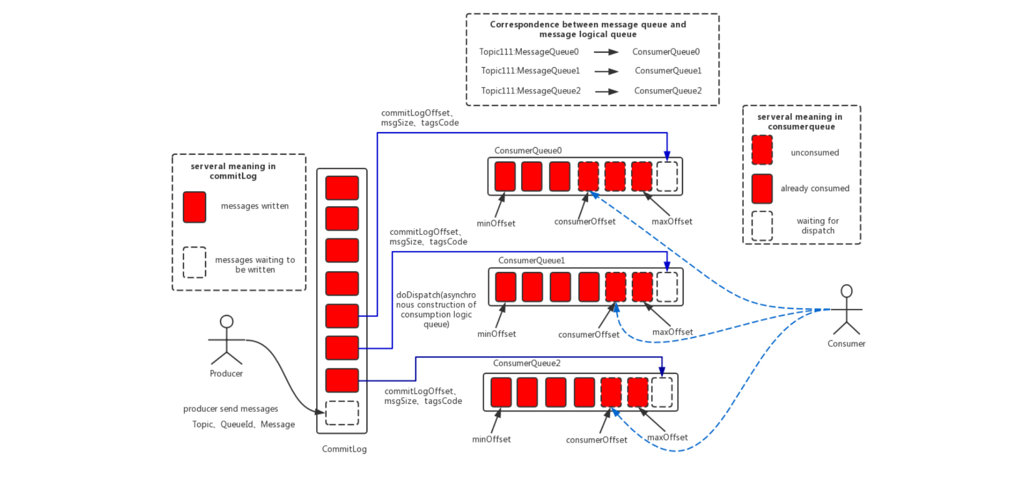
如图:消息被不停的 append 到 commitlog,然后,再构建消费索引,如果没有这个索引,consumer 要在 commitlog 里消费消息,那可真是太难了(慢慢遍历?)。
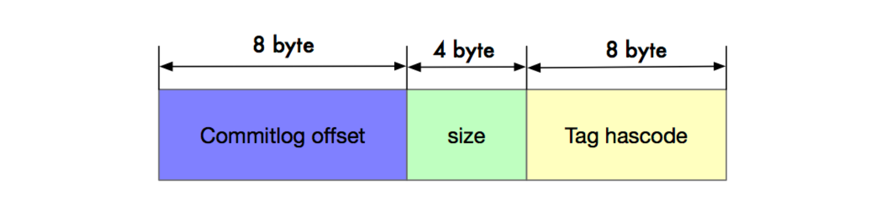
每个 consumerQueue 文件里存放着 3ow 个元素,每个元素 20 字节,8 字节 offset ,4 字节 size, 8 字节 tag hashcode,因此,每个文件也就 5.8MB 不到,很轻量。
Hash 查询索引
Hash 查询索引,主要是根据 Key 来快速查询消息,属于一种附加功能。RocketMQ 采用了 Java HashMap 的思想,实现了 Hash 索引的存储。
Hash 索引结果如下图:
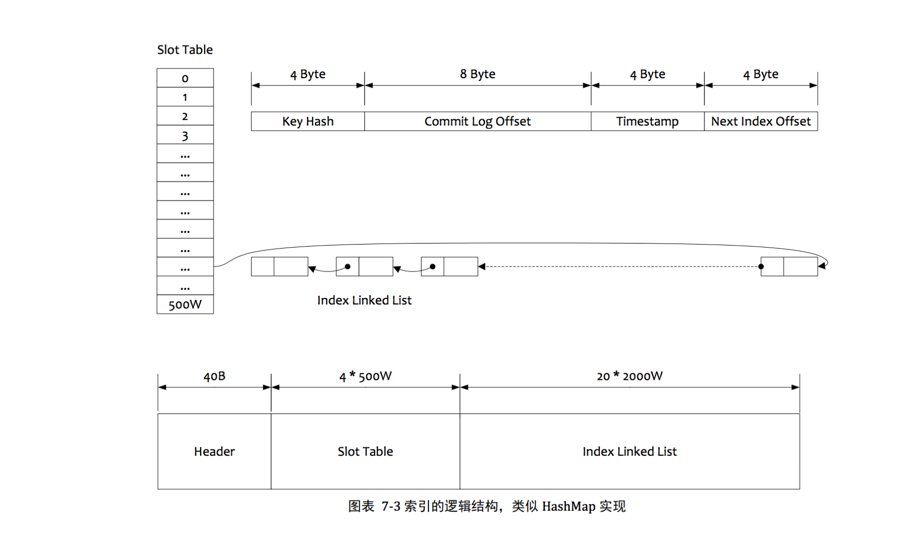
这里我直接使用了 RocketMQ PDF 文档里的图,从图中可以看出,这个 Map 有 500w 个 slot,每个 slot 的链表长度为 4. 如果我们使用一个 key 进行消息查找,他的过程是这样的:先 hash key 得到 hashCode,然后对 5oow 取余,找到槽位,这个槽位大小是 4 个字节,保存了链表尾部的具体元素地址。而这个链表元素的大小是 20 个字节,保存了 key 的 hash 值,commitlog offset,时间戳,还有他下一个链表节点的地址。
为什么在 链表元素里保存 了 hash 值呢?为了防止 hash 值不同,但是 hash 取模后的结果相同(也就是 hash 冲突),如果冲突了,就用 hash 值比对一下。
那如果 hash 值相同,key 内容不同呢?RocketMQ 的做法是放在客户端过滤。
整体处理逻辑和 Java 的 HashMap 类似。
Kafka
鼎鼎大名的 Kafka,可以说强无敌了。今天,我们主要说说他的索引设计。
Kafka 每个 topic 有多个 partition ,每个 partition 有多个 segment,每个 segment 里,存储了消息的相关文件:数据文件,索引文件。
如下图:
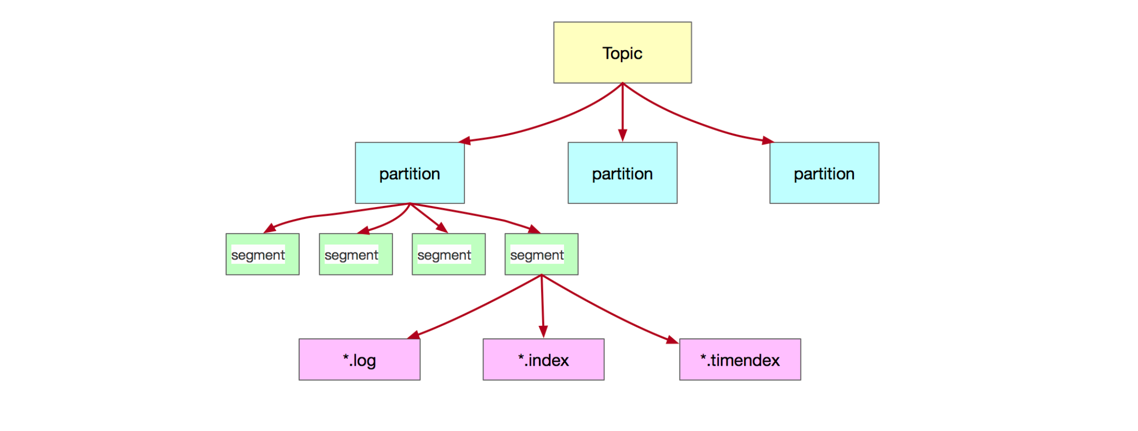
Kafka 不像 RocketMQ,所有数据都存在一个文件里,Kafka 每个 topic 的文件都是隔离开的,而每个 topic 又可能会有很多的 partition(看你的配置),因此,如果你的 topic 非常多,或者你的 partition 非常多的话,顺序写就会变成随机写,性能会骤降(按照 kafka 的说法,可能相差 6,000 倍),这也是我个人认为是两者比较大的区别之一。
Kafka 的索引文件和 数据文件绑定在一起的。这个和 RocketMQ 的 消费索引类似,Kafka 里面是逻辑 offset 映射物理 offset ,并且采用了稀疏索引的方式。然后,我们看看他们的索引设计,如下图:
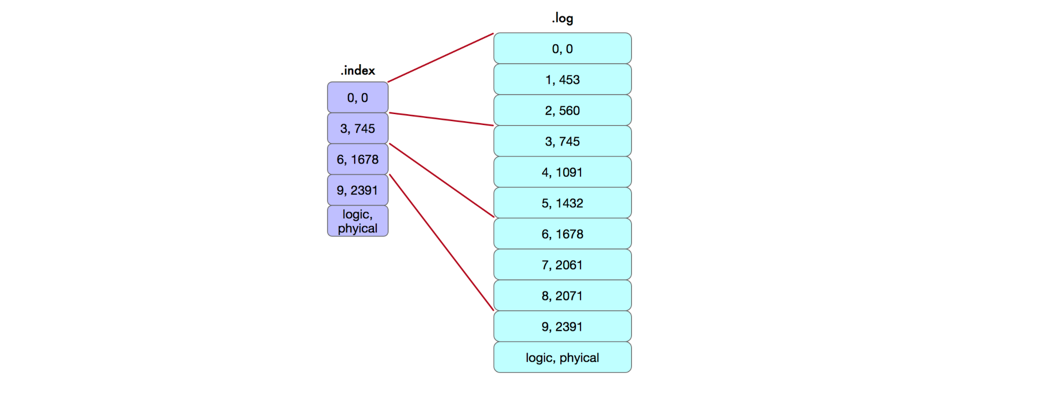
我们以 [3, 495] 为例进行说明,3 表示逻辑索引,即这个 partition 下的全局递增逻辑索引(当然,这个是相对偏移量,这里为了描述简单,就不区分了),495 表示这条消息的所在文件的物理 position。
假设,我现在是一个消费者,订阅了这个 partition 的消息,那么我将从 0 号逻辑索引开始订阅,从 *.index 开始遍历,然后找到对应的物理文件 position.
朋友,kafka 的这个 .index 文件和 RocketMQ 的 consumerQueue 索引,是不是很相似呢?
其实刚开始我一直在想,如果 Kafka 不设计索引行不行?
仔细想想,如果没有索引,如何定位一条消息?每次写入时,都返回一个物理 offset(同时返回 ip、partition、segment 等信息),消费者直接通过这个物理 offset 消费消息。例如 0ffset 362, offset 901 等等。
例如:查找 offset 901消息。通过 服务器 ip+port + topic + partition + segment + offset 901 来找,也不是不可以。但是也太不人性化了吧?
或者,我们直接遍历 .log 文件,从头开始消费。但如果,我不想从头开始消费呢?我想从第 18 条消息开始消费呢?因为没有 .index ,我只能慢慢遍历。
如果我们设计一个索引,一个 topic 设计一个递增的 offset,从 0 开始,每新增一条消息,加一。这是一个逻辑偏移量,我们让逻辑偏移量 映射 物理偏移量。消费者也从 0 开始消费,这样,就达到了某种默契。就算是第 18 条消息,我也能快速找到。
我们看看 kafka 自己怎么说的:

https://kafka.apache.org/082/documentation.html
意思就是:本来我们想用 guid 作为消息的 key 来映射物理 offset 的。但是,仔细一想,不太合适。缺点如下:
- 由于每个消费者都为 broker 维护一个 ID,因此没必要用 guid 这种全局 id ,完全可以在 broker 的基础上,再做唯一 id。
- guid 和物理 offset 的索引映射设计非常的重,耗费资源。
所以,他们搞了一个基于 partition 的分区原子计数器。使用 broker ID + 分区 ID + 计数器 就可以标识一条唯一的消息。然后,用计数器映射 偏移量 offset,简直就是完美。然后,为了达到搜索效率和空间消耗的平衡,边稠密索引为稀疏索引。
总结
好,开始总结。
RocketMQ 和 Kafka 的索引设计相似之处:
RocketMQ 的 topic 和 kafka 的 topic 类似,RocketMQ 的 queue 和 kafka 的 partition 类似,都是为了 scale out。RocketMQ 为每个 queue 设计了 consumerQueue 索引文件,每个文件大小固定 5.8MB;Kafka 为每个 partition 设计了 segment (.index + .log)。也就是说,consumerQueue 索引文件和 segment 的 .index 本质是一样的,都是为了让 consumer 快速找到消息。
最后,他俩的最大不同,就是:RocketMQ 是所有 topic 混合存储,目的是支持更多的 topic,而 Kafka 的 topic 是单独存储,好处是顺序读性能好,另外,根据分区做副本也比较好做。
不得不说,工程设计都是取舍与平衡。得根据实际场景来进行代码设计。
例如,现在有个小公司,想自己实现个消息队列,你会怎么设计呢?